Evaluation of Language Models at the BigScience Workshop
Our researchers are excited to be involved in the collaborative BigScience project
BigScience Workshop
Researchers of the NoOverfitting lab, together with a group of more than 500 researchers from 45 different countries — from France, Canada, US, Japan, Indonesia, Ghana, Ethiopia and many more countries — are excited to be involved in the work on the BigScience project.

(Image credit: https://www.theartofbeingyou.com/nlp)
BigScience is a one-year long research workshop, which aims to improve the scientific understanding of the capabilities and limitations of large-scale neural network models in NLP and to create a diverse and multilingual dataset and a large-scale language model as research artifacts, open to the scientific community. Current large-scale NLP models, such as GPT3, are developed by technology giants who have lots of available resources. As such, these models are private, with only restricted access provided to academic organizations. This makes it very hard to study and evaluate these models’ behaviour, their potential limitations, bias and fairness. The purpose of the BigScience project is to make the NLP open and to share all the findings, models, datasets and tools with the community. The BigScience workshop involves a set of collaborative tasks that are performed by the members of multiple Working Groups - groups on dataset creation, modelling, tokenization, evaluation, interpretability, scaling, and social impact.
Our researchers are members of the Evaluation working group and are involved in the research studying how to make language models “good” using extrinsic, intrinsic and few-shot evaluation methods. The updates on the goals, ongoing progress and future plans of the Evaluation working group were presented today, July 30th 2021, at the BigScience Episode #1 event that was live-streamed on Youtube, and followed by the social networking hour at gather.town.
Evaluation of Language Models
The Evaluation working group now consists of 161 members and 8 chairs. The main goal of the group is 1) to develop standardised measures for evaluating models, and 2) to design a diverse, multifaceted suite of evluations that represents the different ways in which people use language models in practice, and the different scientific communities who are interested in the capabilities of language models.
As this goal is broad enough, the group was naturally divided into five smaller subgroups to ensure that all differing priorities are fully covered: extrinsic evaluation, intrinsic evaluation, few-shot generalization, bias and social impact and multilingualism:
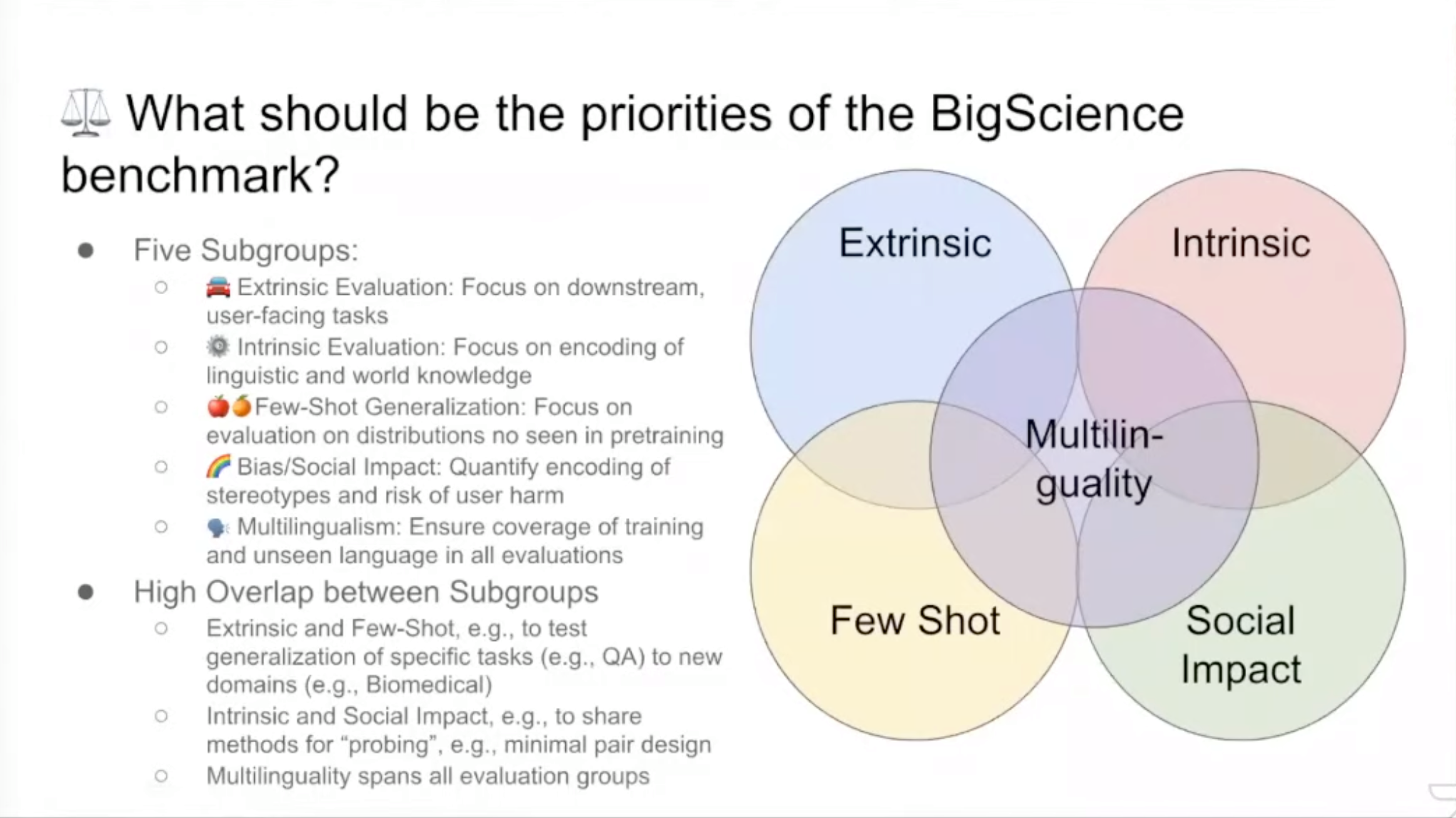
(Image credit: BigScience Episode #1event)
Over the course of several months we worked in these small groups to do literature review, establish research questions and establish evaluation criteria. We have aggregated over 70 candidate datasets across different domains (sentiment analysis, summarization, social bias, dialogue, machine translation, common sense etc.), languages (English, Spanish, French etc.) and formats (multiple choice classification, generation, reading comprehension, etc). Out of these, the top-choice subset was selected during a “sales pitch” internal meeting, where each dataset was presented by their advocates and its significance, strengths and limitations were presented and discussed. As a result, the following datasets made it to the final short list, which will be used to evaluate the final model:
-
7 Extrinsic Tasks: MT (WMT, DiaBLa); QA (TyDiQA,XQuAD); Summarization (CRD3); Generation (GEM); Classification (SuperGLUE)
-
8 Intrinsic Tasks: Syntax (UD, BLiMP, Edge Probing, LinCE); NER (MasaskhaNER, WikiANN); SRL (QA-SRL); Language Modeling (Flores 101); World Knowledge (LAMA)
-
9 Few-Shot Tasks: Unseen Domain (BioASQ, QASPER); Unseen Task (MNLI, ANLI, HANS); Unseen Language (TyDiQA); Unseen Labels (HuffPo)
-
4 Bias/Social Impact Tasks: Gender Bias (WinoMT); Toxicity and Social Identity (Jigsaw); Social Stereotypes (CrowS-pairs); Minimal Pair Tests
-
Multilinguality Integrated Throughout: Training languages in TyDiQA/UD, African Languages in MasaskhaNER, etc.
Next Steps and Future Work
The next immediate step on the road towards delivering the final benchmark is to standardise all the chosen datasets and metrics in one shared repository, write or reformat prompts that will be necessary for certain model testing regimes, and measure the computer usage for carbon footprint tracking. The longer term plan is to develop evaluations that do not exist but should.