What Checklist Know about Depression Detection Models?
We have conducted research on whether BERT models are able to successfully learn depression specific language markers and symptoms from text.
Motivation
With the coronavirus pandemic setting off the worst mental health crisis of the 21st century we recognized the importance of having models that can accurately classify depression from text.
Naturally, our attention turned to the pre-trained transformers that have been revolutionizing the NLP industry, specifically BERT-based models. However, there have been observations about the lack of generalizability and inconsistencies in performance results. Thus, this motivated us to explore in greater detail these models’ performance on depressive text.

(Image credit: https://media-cldnry.s-nbcnews.com)
Related Work
After exploring various evaluation techniques we have picked the CheckList from

(Image credit: https://www.shutterstock.com)
We were interested to test whether BERT-based models are able to learn depression specific language markers from text. For example, many studies show that increased usage of first-person pronouns can be a reliable indicator of the onset of depression as a person becomes self-focused in their speech

(Image credit: https://www.shutterstock.com)
Further,

(Image credit: https://www.shutterstock.com)
Methodology
To create all our behavioral tests we used the dataset of tweets for depression detection collected by
We created four MFT and two INV tests to assess whether a model learns the link between personal pronouns usage and depression. For MFT we took the subset of data with the label “non-depressed” and replaced all “I” pronouns with “She”, “He”, “They”. We considered a test to fail when a model predicted these tests as “depressed” class. We did exactly the opposite by replacing “She”, “He”, “They” with “I” and establishing a failure criteria when the model predicts this test as “non-depressed”. For the two INV tests we took data from both classes and swapped “He” with “She” and the other way around. We considered the model to fail if there was a change in the predicted class.
For DIR tests we created two tests for eight out of PHQ-9 symptoms, one test for presence of a symptom in text and another for absence of such a symptom. For example, for the depression symptom “lack of energy” we added sentences “I feel tired all the time” to “depressed” class to indicate presence of a symptom and “I feel rested and full of energy” to “non-depressed” class to show its absence. We then measure the change in direction of prediction with the failure criteria that the change can only be towards the class label.
Data, Models and Experiments
We tested three sets of classifiers fine-tuned from three different, pre-trained BERT variants: BERT, RoBERTa, and ALBERT, downloaded from Huggingface.
We trained these models on a balanced dataset of 23,454 tweets, TWSELFDIAG, that we created from
We were interested if standard performance metrics were fully representative of the capabilities and limitations of BERT-based models in recognizing signs of depression from text. As such, we first performed In-Distribution (ID, same distribution as training data) classification experiments by training each of three models on the training subset of TWSELFDIAG and testing them on the test subset of the same TWSELFDIAG dataset. We selected the best performing model for BERT, RoBERTa and ALBERT based on the standard evaluation metrics of Accuracy, AUC and Brier score, for use in further experiments. Next, we wanted to see the generalizability of these models by testing them on OOD, the three datasets mentioned above. Finally, we assessed models performance on our depression behavioral tests and compared the results with standard performance metrics and OOD results.
Results
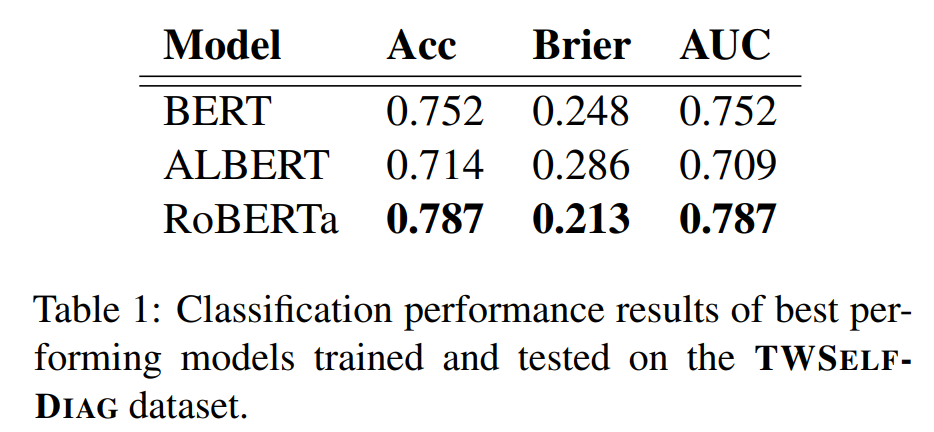
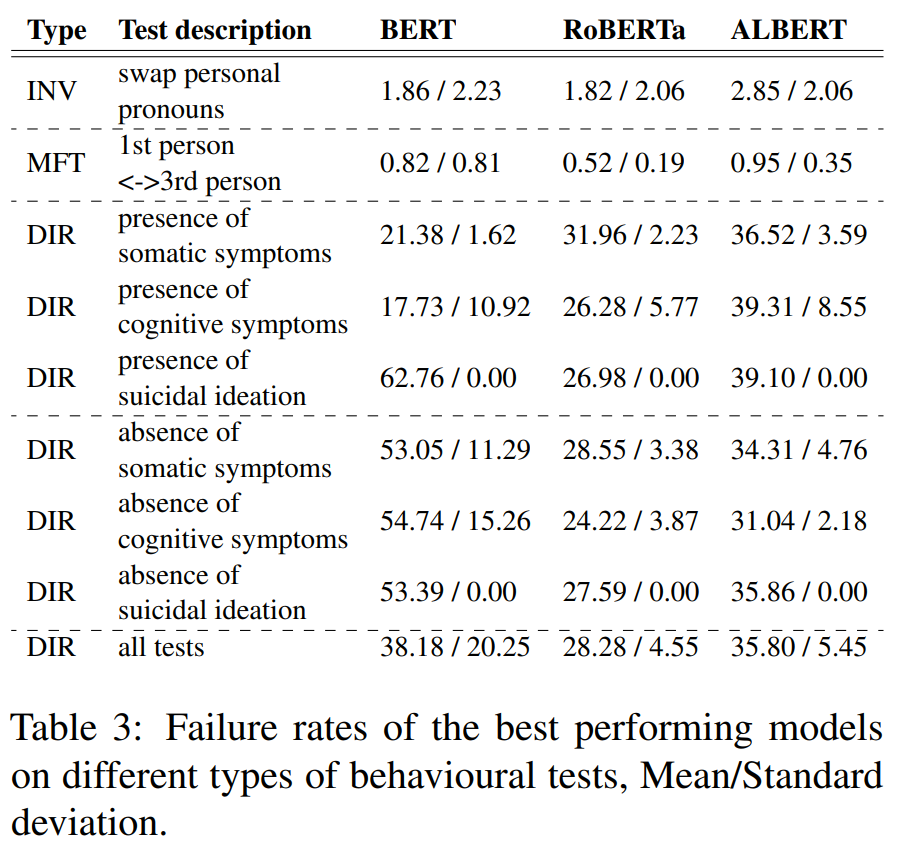
The results show that the best performing RoBERTa is able to achieve the highest classification performance based on accuracy, Brier and AUC scores and ALBERT is the worst model (Tab.1). This follows the order of the behavioral testing performance across MFT and INV tests (Tab. 3) and thus suggests that valuation metrics may be good in assessing capability of models in terms of its basic functionality (e.g. detecting most common and most generic depression-based language patterns), as well as models’ robustness against simple perturbations.
Failure rates of all three models on the DIR tests are substantially higher than those on the INV and MFT tests indicating that the models are not capable of detecting these specifics in text with sufficient accuracy. Across DIR tests the somatic symptoms prove to be easier to detect. Suicidal ideation is the most difficult symptom of depression for the models to detect.
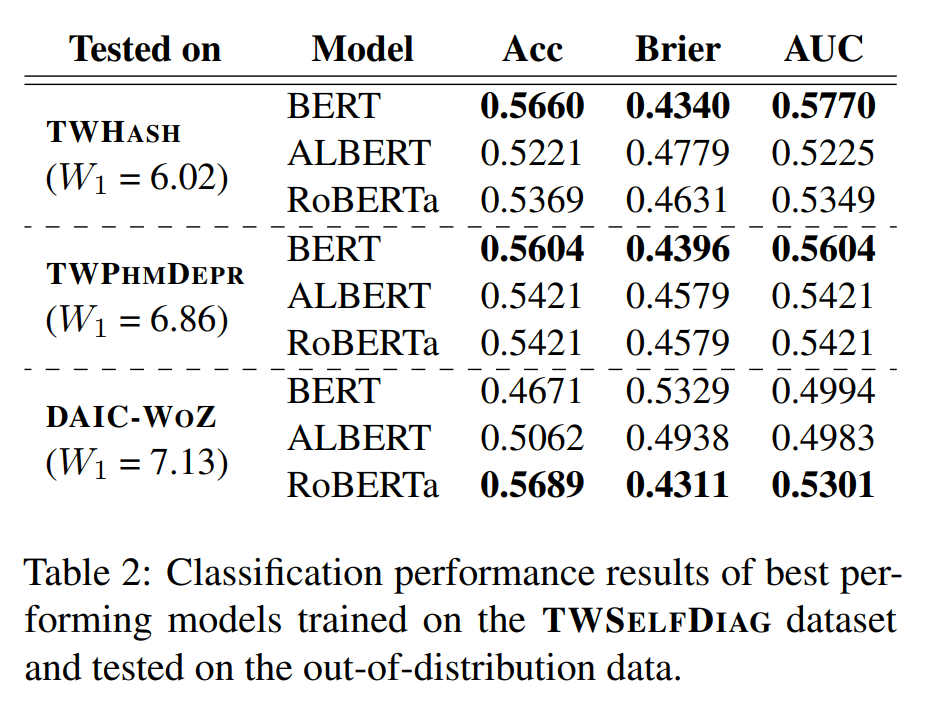
If we order the models according to their behavior on the DIR tests that are based on the presence of depression symptoms, BERT is the best performer with RoBERTa coming next and ALBERT being the worst (Tab. 3). Interestingly, model performance in OOD settings of small/medium distance follows this same ordering, with BERT achieving the greatest performance and ALBERT achieving the worst (Tab. 2).
Takeaways
RoBERTA’s higher performance suggests that longer training and incorporating more context into the training process can potentially improve model’ capability to recognize the absence of depressive symptoms. A potential way to improve model performance on the DIR tests of type a could be adding symptom-related information to training data before fine-tuning models. However, these results and thus suggestions could only be considered as a preliminary investigation and motivation for future research.